همراهان گرامی در نهمین جلسه از آموزش هوش تجاری قصد داریم شما را با مفهوم Data Flow Task آشنا کنیم. Data Flow Task مهمترین Task موجود در SSIS جهت کار با داده می باشد , که در ادامه به معرفی آن می پردازیم با ما همراه باشید.
معرفی Data Flow Task و شروع کار با آن
Data Flow Task وظیفه انتقال داده بین انواع منابع داده را دارد و در این میان به کاربر اجازه می دهد که داده را پاکسازی و پالایش کند. در واقع Data Flow Task شامل مجموعه ای از Component ها است که وظیفه خواندن داده (Extract) و پاکسازی و پالایش داده (Transform) و بارگزاری (Loading) داده را دارند.
در مرحله اول و برای شروع کار یک Data Flow Task به Control Flow اضافه کنید و روی آن دابل کلیک کنید تا وارد محیط Data Flow شوید.
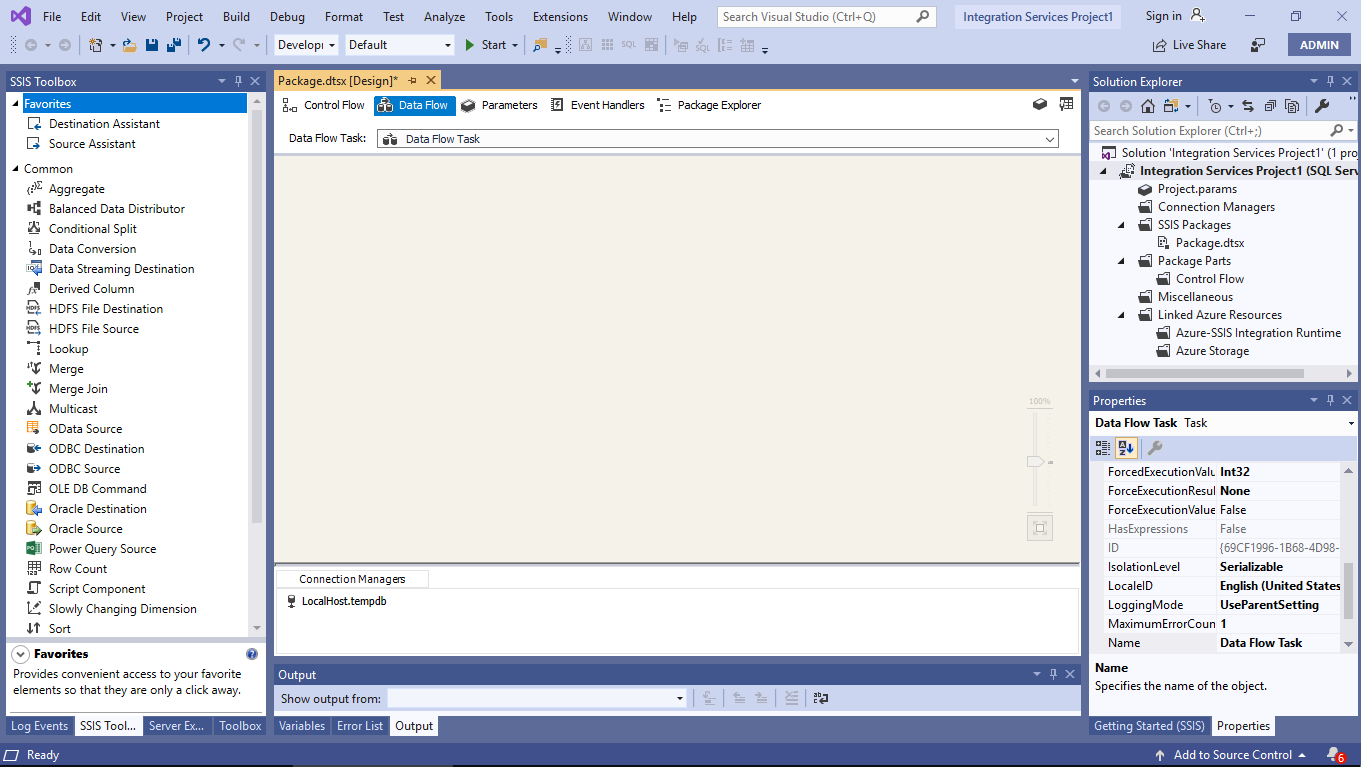
همان طور که مشاهده می کنید هنگامی که در تب Data Flow هستید در پنجره SSIS Toolbox لیست Component ها ظاهر می شود.
Component ها در SSIS Toolbox در سه دسته تقسیم می شوند:
# در این جلسه و جلسات بعدی قصد داریم در مثال های مختلف به معرفی Component های Data Flow Task بپردازیم .
معرفی Component های OLE DB Source و Sort و Merge Join و OLE DB Destination در قالب مثال
در مثال زیر قصد داریم داده موردنیاز را از جداول [Sales].[SalesOrderHeader] و [Sales].[SalesOrderDetail] از پایگاه داده AdventureWorks2017 را بخوانیم و سپس آن ها را join کنیم و در نهایت در یک جدول جدید بریزیم.

پایگاه داده AdventureWorks2017 را می توانید از این آدرس دانلود کنید.
برای شروع ابتدا 2 OLE DB Source و 2 Sort و یک Merge Join و یک OLE DB Destination به صفحه Data Flow اضافه کنید و سپس آن ها را به هم متصل نمایید. خطی که Component ها را به هم متصل می کند Data Flow Path نام دارد که در جلسه بعدی در مورد آن توضیح خواهیم داد.
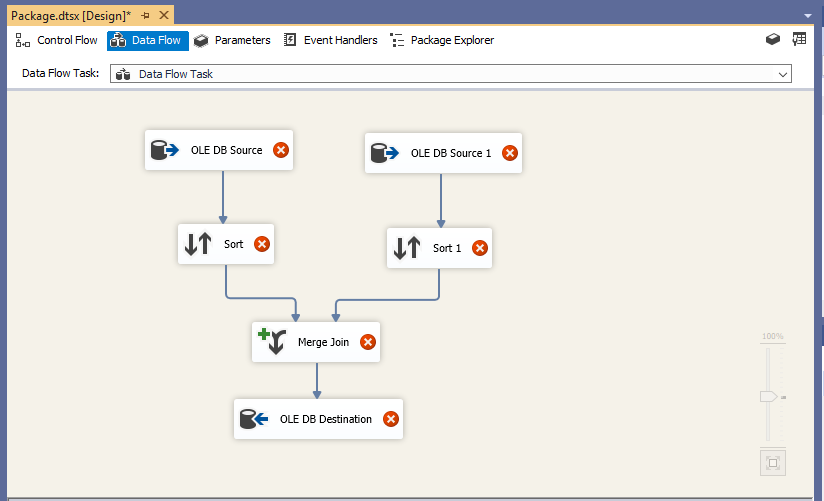
- تنظیم OLE DB Source

همانطور که گفتیم از component هایSource برای خواندن داده از منابع داده مختلف استفاده می کنیم. در این مثال برای خواندن جداول مورد نظر از OLE DB Source استفاده می کنیم. OLE DB Source توانایی خواندن داده از منابع داده مختلف مانند SQL Server یا Access که از OLE DB پشتیبانی می کنند را دارد.
برای تنظیم OLE DB Source روی آن دابل کلیک کنید.
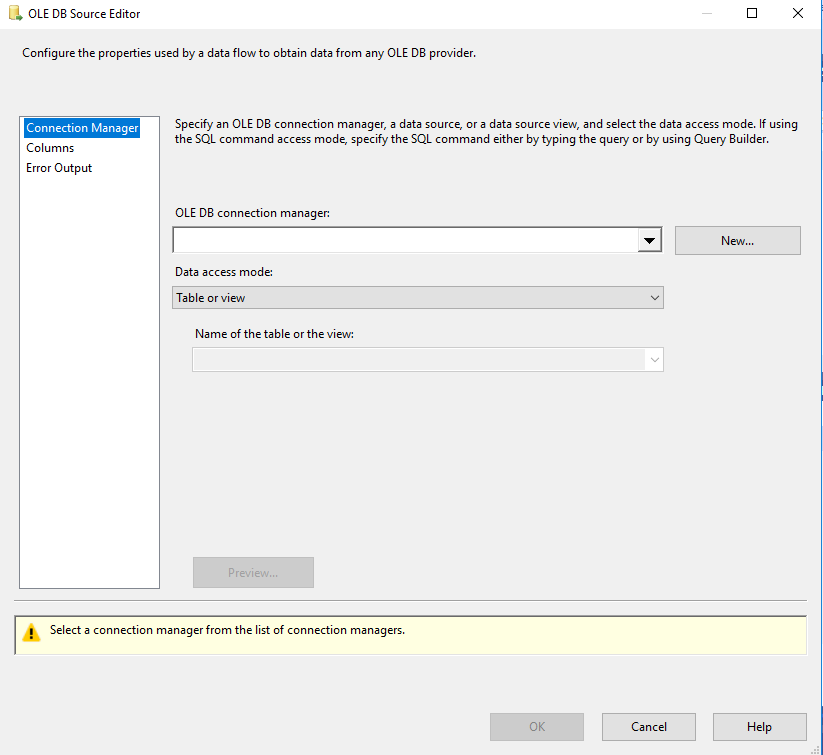
گام اول : ابتدا باید در قسمت OLE DB Connection Manager یک OLE DB Connection ایجاد و یا از منوی بازشو انتخاب کنید. اگر از قبل OLE DB Connection ایجاد کردید می توانید از Combo Box موجود در قسمت OLE DB Connection Manager آن را انتخاب کنید و یا روی دکمه New کلیک کنید تا وارد صفحه Configure OLE DB Connection Manager شوید.
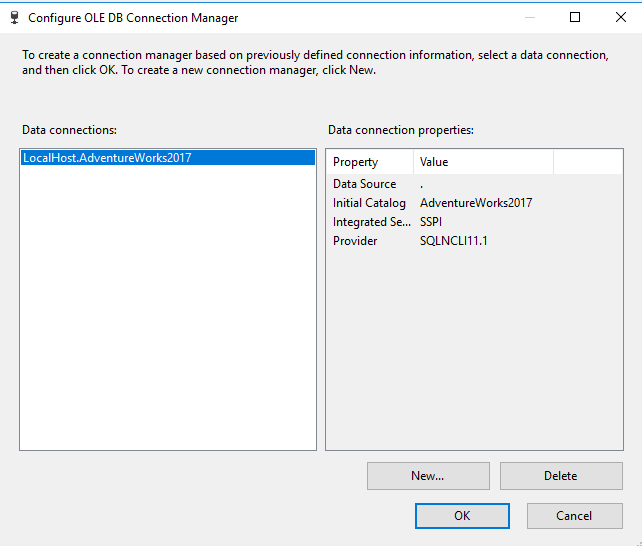
همان طور که مشاهده می کنید در قسمت Data Connection لیست Data Connection هایی که از قبل ایجاد شدند نشان داده شده اند. با کلیک بر روی هر یک از Data Connection ها می توانید خصوصیات آن را در قسمت Data Connection Properties مشاهده کنید. برای ایجاد یک Data Connection جدید روی دکمه New کلیک کنید تا وارد صفحه Connection Manager شوید.

در حالت کلی Data Access Mode دارای 4 گزینه است که عبارتند از:
- اگر گزینه Table Or View را انتخاب کنید باید در قسمت Name Of The Table Or The View نام جدول یا View مورد نظر خود را انتخاب کنید.
- اگر گزینه Table Name Or View Name Variable را انتخاب کنید باید در قسمت Variable Name متغیر مورد نظر خود را انتخاب کنید. در واقع این گزینه می گوید که نام جدول یا View مورد نظر در یک متغیر می باشد.
- اگر گزینه SQL Command را انتخاب کنید در قسمت SQL Command Text باید دستور T_SQL مورد نظر را وارد کنید.
- اگر گزینه SQL Command Variable را انتخاب کنید باید در قسمت Variable Name متغیر مورد نظر خود را انتخاب کنید . در واقع این گزینه می گوید که دستور T_SQL مورد نظر در یک متغیر می باشد .
گام ششم : حال به تب Columns بروید تا ستون های مورد نظر شناسایی شوند. همچنین در قسمت Available External Columns می توانید تیک ستون هایی را که نمی خواهید بردارید. در قسمت Output Column می توانید اسم مستعار (Alias) برای ستون مورد نظر خود تعیین کنید.

پس از انجام تنظیمات مورد نظر روی OK کلیک کنید.
برای این مثال
– ابتدا در قسمت OLE DB Connection Manager یک Connection جهت ارتباط با دیتابیس AdventureWorks2017 ایجاد کنید.
– در قسمت Data Access Mode گزینه Table Or View را انتخاب کنید.
– در قسمت Name Of The Table Or The View جدول [Sales].[SalesOrderHeader] را انتخاب کنید.
– در تب Columns فقط ستون های [SalesOrderID],[OrderDate],[DueDate],[ShipDate] را انتخاب کنید.
توجه : تنظیم OLE DB Source دوم نیز مانند OLE DB Source اول است با این تفاوت که به جای جدول [Sales].[ SalesOrderHeader] جدول [Sales].[SalesOrderDetail] را انتخاب کنید و در تب Columns فقط ستون های [SalesOrderID],[SalesOrderDetailID],[OrderQty],[ProductID] ,[UnitPrice] را انتخاب کنید.
- تنظیم Sort
Merge Join یکی از Component های SSIS می باشد که برای پیوند زدن دو جدول به صورت افقی (Horizontal Join) استفاده می شود. Merge Join نیاز به ورودی مرتب شده بر اساس شروط Join دارد. برای مرتب سازی داده در SSIS از کامپونت Sort استفاده می کنیم. برای تنظیم Sort روی آن دابل کلیک کنید.


Comparison Flag : ستون Comparison Flag تنها برای ستون های از جنس متن فعال است که دارای مقادیر زیر است :
- Ignore Case : حساس به حروف کوچک و بزرگ نمی شود. به عنوان مثال ABC برابر با abc می باشد.
- Ignore kana type : این گزینه مربوط به زبان ژاپنی است. اگر تیک این گزینه را فعال کنید تفاوت بین hiragana و katakana ژاپنی نادیده گرفته می شود.
- Ignore character width : اگر این گزینه را فعال کنید در هنگام مرتب سازی از حجم کاراکتر ها صرفه نظر می کند. همان طور که می دانید حجم برخی از کاراکتر ها یک بایت و برخی دو یا چند بایت است.
- Ignore non spacing characters : اگر این گزینه فعال شود در هنگام مرتب سازی از کاراکتر های علامت (ئ ، ؤ ، إ ، أ ، ــًــٍــٌـ و …..) صرفه نظر می شود. به عنوان مثال ، “Ã ¥” برابر می شود با “a”.
- Ignore symbols : اگر این گزینه فعال شود در هنگام مرتب سازی از کاراکتر های نماد ($ ، % ، & ، * و ….) صرفه نظر می شود . به عنوان مثال “* ABC” برابر می شود با “ABC”.
- تنظیم Merge Join
حالا نوبت به تنظیم Merge Join میرسد. همانطور که گفتیم Merge Join یکی از Component های SSIS می باشد که برای پیوند زدن دو جدول به صورت افقی (Horizontal Join) استفاده می شود. برای تنظیم Merge Join روی آن دابل کلیک کنید.

پس از تنظیم Merge Join روی OK کلیک کنید .
- تنظیم OLE DB Destination
حال نوبت به تنظیم OLE DB Destination میرسد. از OLE DB Destination برای بارگزاری داده در منابع داده مختلف مانند SQL Server یا Access که از OLE DB پشتیبانی می کنند استفاده می کنیم . برای تنظیم آن روی آن دابل کلیک کنید.

نکته : Data Access Mode دارای 4 حالت به شرح زیر است :
- Keep Nulls : زمانی که برای یک ستون مقدار Default تعیین می کنید و هنگامی که در آن ستون مقدار Null ذخیره می کنید آنگاه به جای مقدار Null مقدار Default تعیین شده ذخیره می شود. اگر گزینه Keep Nulls را فعال کنید در ستون مقصد به جای مقدار Default مقدار Null ذخیره می شود.
- Table Lock : جدول مورد نظر را تا پایان عملیات Lock می کند. فعال سازی این گزینه می تواند باعث افزایش سرعت شود.
- Check Constraints : اگر این گزینه فعال باشد داده ورودی را هنگام بارگزاری در جدول مقصد با توجه به Check Constraint های ایجاد شده بر روی جدول بررسی می کند.
- Rows per batch : مشخص می کند که در هر بسته ( Batch) حداکثر چند رکورد در جدول مقصد بارگزاری شود.
- Maximum Insert Commit Size : مشخص می کند که حداکثر حجم هر بسته ( Batch) چقدر باشد.
پس از تنظیم تب Connection Manager به تب Mappings بروید تا ستون های ورودی را با ستون های جدول مقصد مورد نظر Map کنید . SSIS به صورت پیشفرض از روی نام ستون ها ، ستون های ورودی و جدول مقصد را باهم Map می کند . توجه داشته باشید که ممکن است که SSIS برخی از Mapping ها را تشخیص نداده باشد ، پس به دقت این تب را بررسی کنید.
پس از انجام تنظیمات روی OK کلیک کنید .
این مثال به پایان رسید . کافیست که F5 را بزنید تا پکیج اجرا شود . حال به دیتابیس و جدول مقصد رجوع کنید تا نتیجه کار را مشاهده کنید.